Integration Information Model
| Issuer: openEHR Specification Program | |
|---|---|
Release: RM Release-1.1.0 |
Status: STABLE |
Revision: [latest_issue] |
Date: [latest_issue_date] |
Keywords: EHR, integration, openehr |
|
| © 2003 - 2021 The openEHR Foundation | |
|---|---|
The openEHR Foundation is an independent, non-profit foundation, facilitating the sharing of health records by consumers and clinicians via open specifications, clinical models and open platform implementations. |
|
Licence |
|
Support |
Issues: Problem Reports |

Amendment Record
| Issue | Details | Raiser | Completed |
|---|---|---|---|
RM Release 1.1.0 |
|||
RM Release 1.0.4 |
|||
Release 1.0.1 |
|||
SPEC-203: Release 1.0 explanatory text improvements. Added section on openEHR Extract. Added integration architecture diagram. |
T Beale |
||
Release 1.0 |
|||
0.5 |
Initial writing. |
T Beale |
15 Sep 2005 |
Acknowledgements
The work reported in this paper has been funded in part by the following organisations:
-
University College London - Centre for Health Informatics and Multi-professional Education (CHIME);
-
Ocean Informatics.
Special thanks to David Ingram, Emeritus Professor of Health Informatics at UCL, who provided a vision and collegial working environment ever since the days of GEHR (1992).
1. Preface
1.1. Purpose
This document describes the architecture of the openEHR Integration Information Model, designed for use in legacy and other integration situations.
The intended audience includes:
-
Standards bodies producing health informatics standards;
-
Academic groups using openEHR;
-
The open source healthcare community;
-
Solution vendors;
-
Medical informaticians and clinicians interested in health information.
-
Health data managers.
1.3. Status
This specification is in the Stable state. The development version of this document can be found at https://specifications.openehr.org/releases/RM/latest/integration.html.
Known omissions or questions are indicated in the text with a 'to be determined' paragraph, as follows:
TBD: (example To Be Determined paragraph)
1.4. Feedback
Feedback may be provided on the openEHR RM specifications forum.
Issues may be raised on the specifications Problem Report tracker.
To see changes made due to previously reported issues, see the RM component Change Request tracker.
1.5. Conformance
Conformance of a data or software artifact to an openEHR specification is determined by a formal test of that artifact against the relevant openEHR Implementation Technology Specification(s) (ITSs), such as an IDL interface or an XML-schema. Since ITSs are formal derivations from underlying models, ITS conformance indicates model conformance.
2. Integration Package
2.1. Requirements
Getting data in and out of the EHR is one of the most basic requirements openEHR aims to satisfy. In "greenfield" (new build) situations, and for data being created by GUI applications via the openEHR EHR APIs, there is no issue, since native openEHR structures and semantics are being used. In almost all other situations, existing data sources and sinks have to be accounted for. In general, external or 'legacy' data (here the term is used for convenience, and does not imply anything about the age or quality of the systems in question) have different syntactic and semantic formats than openEHR data, and seamless conversion requires addressing both levels.
Typical examples of legacy data sources and sinks include relational databases, HL7v2 messages, and HL7 CDA documents. HL7v2 messages are probably one of the most common sources of pathology messages in many countries; EDIFACT messages are another. More recently, HL7v2 messages have been designed for referrals and even discharge summaries. Not all legacy systems are standardised; many if not most hospitals as well as GP and other desktop products have their own private models of data and terminology usage. Technically speaking, there is not much difference between standardised and non-standardised legacy models; only the reusability of the solution differs.
Another important category of externally sourced data addressed by the Integration package
described here is data expressed in a form of a ISO 13606 Extract. Part 1 of ISO 13606 defines a
information model which is nearly identical to that of openEHR at the COMPOSITION and SECTION
levels. The ISO 13606 Entry class is a generic structure with a minimum of contextual metadata,
and can easily be mapped to the openEHR Entry type described in this specification.
The primary need with respect to legacy data is to be able to convert data from multiple mutually incompatible sources into a single, standardised patient-centric EHR for each patient, that can then be longitudinally viewed and queried. This is what enables GP and specialist notes, diagnoses and plans to be integrated with laboratory results from multiple sources, patient notes, administrative data and so on, to provide a coherent record of the patient journey.
In technical terms, a number of types of incompatibility have to be dealt with. There is no guarantee
of correspondence of scope of incoming transactions and target openEHR structures - an incoming
document for example might correspond to a number of clinical archetypes. Structure will not usually
correspond, with legacy data (particularly messages) usually having flatter structures than those
defined in target archetypes. Terminology use is extremely variable in existing systems and messages,
and also has to be dealt with. Data types will also not correspond directly, so that for example, a mapping
between an incoming string "110/80 mmHg" and the target openEHR form of two
DV_QUANTITY objects each with their own value and units has to be made.
2.2. Design Basis
2.2.1. Overview
The design basis for connecting existing systems to openEHR is founded upon a clear separation of the syntactic and semantic transformations required on data. The syntactic transformation converts source data from its original form (or whatever intermediate form it may have been converted to) to a format obeying a special class in the openEHR reference model, but whose logical structure and semantics are controlled by 'integration' archetypes so as to mimic the design of the source data. This step brings the data into the openEHR computational context. The second step causes transformation on this intermediate openEHR data into data which are a) instances of the main openEHR reference model, and b) obey 'designed' clinical archetypes.
The additional elements of the openEHR architecture which make this transformation possible are:
-
a class
GENERIC_ENTRY, which is a sibling ofSECTIONandENTRY, and contains completely generic, archetypable structures; -
'integration' archetypes, i.e. archetypes defined against the
GENERIC_ENTRYclass; -
semantic transformation rules from openEHR data based on
GENERIC_ENTRYand integration archetypes to data based on the subtypes ofENTRY, and designed archetypes.
The figure below illustrates the rm.integration package, which contains a single class
GENERIC_ENTRY. Unlike other classes in the openEHR reference model, GENERIC_ENTRY contains
no hard-wired attributes at all, only one generic attribute, data. No assumptions at all are made about
the actual shape of such data.

2.2.2. Semantics of GENERIC_ENTRY
A number of useful consequences follow from this modelling approach. Firstly, instances of
GENERIC_ENTRY will contain attributes inherited from the LOCATABLE class, including
archetype_node_id, and are thus archetypable in the same way as all other classes in the openEHR
reference model. The LOCATABLE attribute feeder_audit is also inherited, and may be used to mark
every node of data with relevant meta-data from the source system record or message. Secondly, as a
subtype of CONTENT_ITEM, GENERIC_ENTRY is a valid value for COMPOSITION.content. This is a
completely desirable situation, since the same rules apply to GENERIC_ENTRY as to other content:
instances can only be committed to the record as part of a COMPOSITION instance. GENERIC_ENTRY
data are thus audit-trailed and versioned in the normal way. Thirdly, GENERIC_ENTRY instances can
occur within a hierarchy of SECTIONs, which is useful for data sources which have headings or section
equivalents (this is quite common in hospital information systems containing physician notes).
Lastly, in common with all other openEHR data, design-time paths can be constructed for archetypes
of GENERIC_ENTRY, while runtime paths can be extracted from data based on such archetypes. These
path sets can be used for writing the data transformation rules.
It should be remembered that while GENERIC_ENTRY provides a standardised syntactic form for
externally sourced data within openEHR, it provides no semantic coherence. This is particularly true
for GENERIC_ENTRY instances sourced from numerous data sources: there is no guarantee that the
GENERIC_ENTRY representations of "cholesterol result" from system A will be congruent with those
sourced from system B. It is not even required that the data sources be vastly different for this problem
to occur. Examples of messages can be found coming from different pathology laboratories,
which obey the same minor version of HL7v2 (e.g. 2.3.1) and supposedly implement the same message
type (e.g. "complete blood picture") but which differ in actual structure and content.
The consequence of this situation is that GENERIC_ENTRY data cannot in general be safely used for
clinical computation (e.g. decision support), and will not in general even support reliable clinical querying.
In other words, a repository of GENERIC_ENTRYs (within appropriate COMPOSITION structures)
does not constitute a reliable or interoperable health record - it can only be considered a
standardised health information data store whose primary purpose is as the input to or output of
semantic conversion processes, or for other auditing or non-clinical data management purposes.
2.2.3. Use with openEHR Extracts
The GENERIC_ENTRY class provides a way to represent data from non-openEHR systems that implement
the openEHR Extract specification in order to either communicate with openEHR systems, or to
communicate with other systems also implementing the openEHR Extract specification.
2.2.4. Integration with ISO 13606
The GENERIC_ENTRY class provides a convenient basis for making openEHR systems ISO 13606-
compliant, which in turn gives openEHR a gateway capability in heterogeneous environments where
ISO 13606 is being used to communicate data. A ISO 13606 EHR Extract can be converted to a
series of COMPOSITIONs containing GENERIC_ENTRY objects which obey appropriate integration
archetypes; this data can then be semantically converted into orthodox openEHR objects for integration
into a coherent EHR. Similarly, openEHR data can be converted into the GENERIC_ENTRY-based
intermediate form for further conversion into ISO 13606 EHR Extracts.
2.3. Data Conversion Architecture
The integration archetype-based strategy for importing data into an openEHR system, shown in the following figure, consists of two steps.
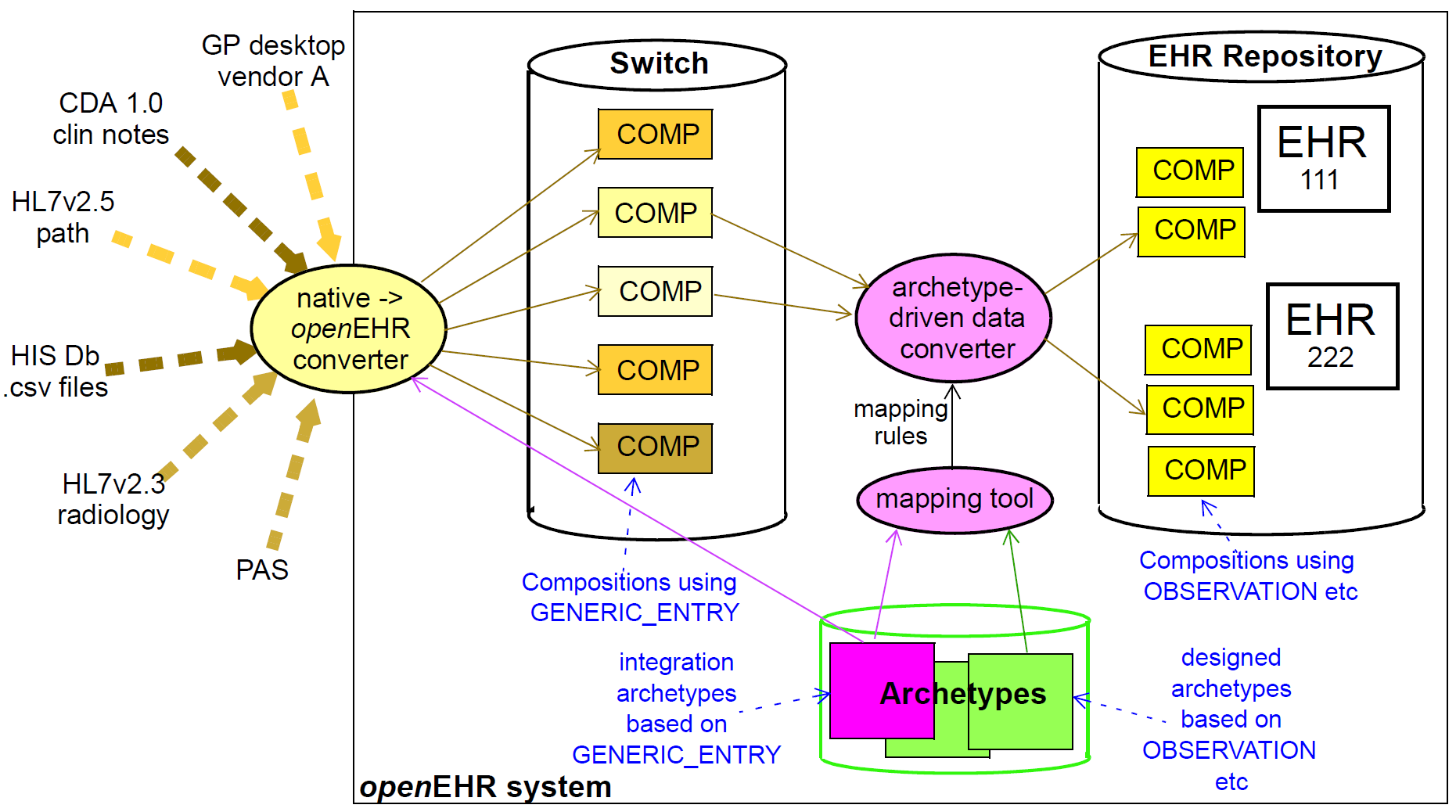
Firstly, data are converted from their original syntactic format into openEHR COMPOSITION/SECTION/
GENERIC_ENTRY structures, shown in the openEHR integration switch. Most of the data will
appear in the GENERIC_ENTRY part, controlled by an integration archetype designed to mimic the
incoming structure (such as an HL7v2 lab message) as closely as possible; FEEDER_AUDIT structures
are used to contain integration meta-data. The result of this step is data that are expressed in the
openEHR type system (i.e. as instances of the openEHR reference model), and are immediately amenable
to processing with normal openEHR software.
In the second step, semantic transformation is effected, by the use of mappings between integration and designed archetypes. Such mappings are created by archetype authors using tools. The mapping rules are the key to defining structural transformations, use of terminological codes, and other changes. Serious challenges of course remain in the business of integrating heterogeneous systems; some of these are dealt with in the Common IM document sections on Feeder systems.
2.4. Class Descriptions
2.4.1. GENERIC_ENTRY Class
Class |
GENERIC_ENTRY |
|
|---|---|---|
Description |
This class is used to create intermediate representations of data from sources not otherwise conforming to openEHR classes, such as HL7 messages, relational databases and so on. |
|
Inherit |
||
Attributes |
Signature |
Meaning |
1..1 |
data: |
The ‘data’ from the source message or record. |